DuReader-retrieval: A Large-scale Chinese Benchmark for Passage Retrieval from Web Search Engine
Abstract
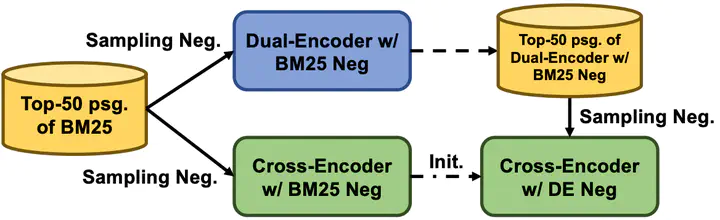
In this paper, we present DuReader-retrieval, a large-scale Chinese dataset for passage retrieval. DuReader-retrieval contains more than 90K queries and over 8M unique passages from Baidu search. To ensure the quality of our benchmark and address the shortcomings in other existing datasets, we (1) reduce the false negatives in development and testing sets by pooling the results from multiple retrievers with human annotations, (2) and remove the training queries that are semantically similar to the development and testing queries. Additionally, we provide two out-of-domain testing sets for cross-domain evaluation, as well as a cross-lingual set that has been manually translated for cross-lingual retrieval. The experiments demonstrate that DuReader-retrieval is challenging and there is still plenty of room for improvement, e.g. salient phrase and syntax mismatch between query and paragraph. These experimental results show that the dense retriever does not generalize well across domains, and cross-lingual retrieval is essentially challenging. DuReader-retrieval is publicly available.
Yifu Qiu
PhD student in Natural Language Processing
PhD researcher in foundation models, alignment, and hallucination mitigation.